Intelligent Trash Can
AI Vision-based Trash Classification
Overview
This project began as a school science fair project. A couple classmates and I noticed that we only had one type of trash bin at school, which meant that recyclable items were not being sorted out and properly disposed of. I came up with the idea of a trash can that would sort trash by itself.
At home, we had a trash can with one of those motion-activated lids that had stopped working, which I thought would be perfect for this project. I fixed up the lid by taking it apart and replacing the motor, which had become corroded probably due to liquid in the bin. Now I could begin making.



Implementation
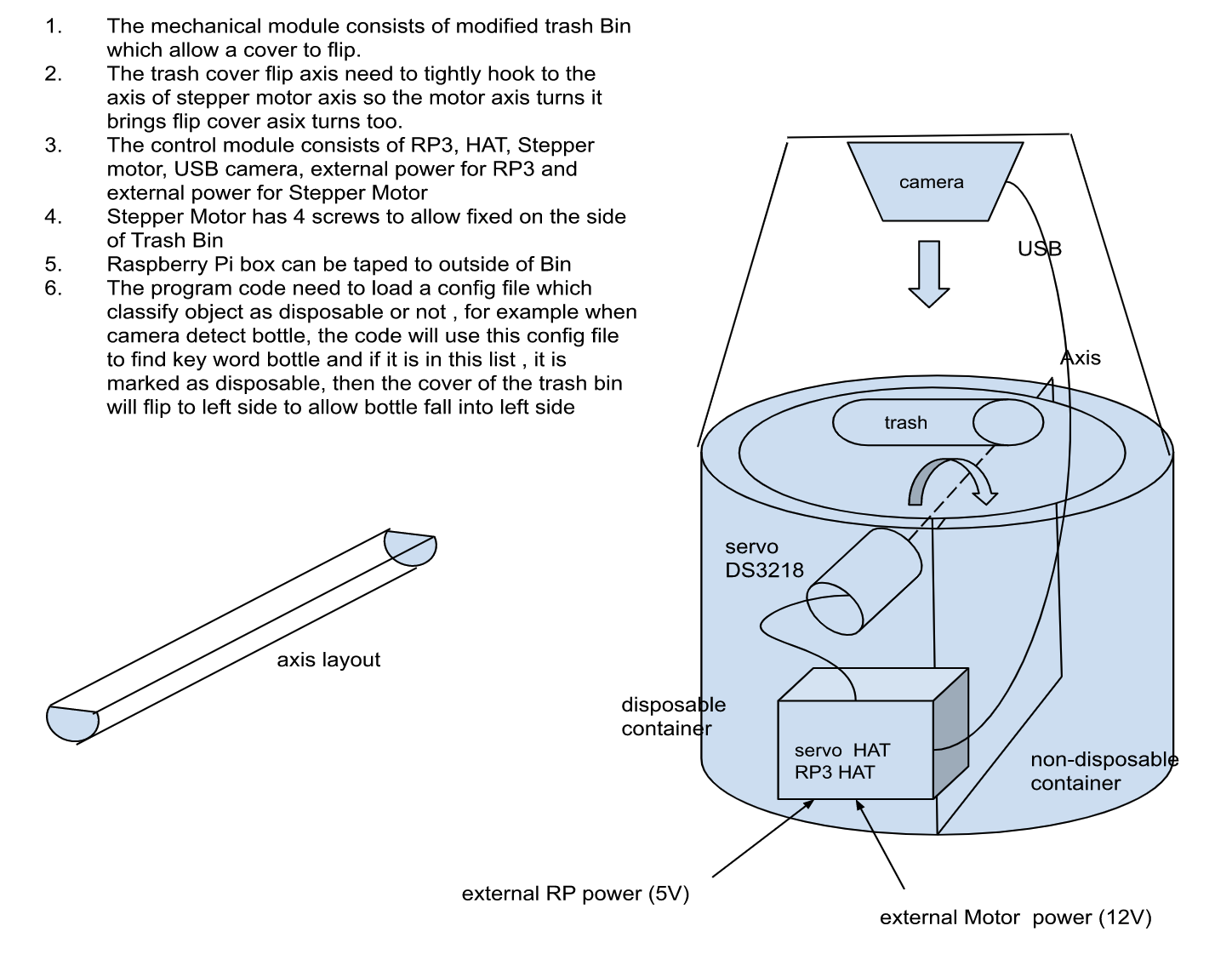
In order to sort the trash, the bin would first have to know what item it was dealing with. The best way would be to use a camera equipped with object detection. By using a polycarbonate platform, the object could be placed in an isolated location to undergo object detection prior to sorting. I thought that the platform could be dual purpose, as it could tilt to release the item into either side of the bin, which I later separated into landfill and recycling sides. A 20kg digital servo and some brackets that I had snagged from my robotics team were adequate in supplying the rotational motion of the flap.
To control the servo from my Raspberry Pi, I would need external power and wiring via a breadboard. However, the Adafruit HAT has external power supply socket so it can power the servo directly. Adafruit also provides some Python example code of how to use it , which was very straightforward to follow.
As for the Pi, I was considering between different operating systems to use for this project. Raspbian Jessie is a good choice: it comes with python3.4 and it is not too outdated.
Originally, my bin functioned by snapping a photo of the trash item inside using an external Pi camera, sending it off to a deep learning computer vision site called Clarifai.ai, and using the outputs from there to determine the type of trash. This worked out in terms of reliability and accuracy, so I stuck with it for a while. However, behind the scenes, I was using a free trial plan from them, meaning that I could only submit up to 500 photos on an account. So between different demos, I was always busy creating loads of new accounts in order for my bin to work.
Later, I found that I could use a Nvidia Jetson TX1 as a CPU for my bin.
Advantages:
- Training and inference can be much faster. Instead of using someone else’s algorithm, I’m using my own.
- Servo can share same hardware and python libary
- Much more Machine learning libary package support such as keras, easier to solve issue
- Better learning platform than RP3 for ML related. Good for doing other projects in future such as vehicle, autonomous drive, robots, etc
- Can use CSI camera for fast and robust processing in future Disadvantages:
- The servo hat will not be compatible with PIN in TX1. The servo board needs to use a jumper to connect to TX1.


Here is the code to training code from the TX1
mobilenet_training.py
Long ago
Feb 15, 2019
You uploaded an item
Text
mobilenet_training.py
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import argparse
import matplotlib as mpl
mpl.use('TkAgg')
import matplotlib.pyplot as plt
import os
import sys
import glob
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split # 0.18
#from sklearn.cross_validation import train_test_split
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, cohen_kappa_score, roc_auc_score, \
roc_curve
from collections import Counter
from sklearn.utils import class_weight
from keras.applications.mobilenet import preprocess_input, MobileNet
from keras.models import Model, load_model
from keras.layers import Dense, GlobalAveragePooling2D
from keras.preprocessing import image
from keras.optimizers import SGD
IM_WIDTH, IM_HEIGHT = 224, 224
NB_EPOCHS = 1
BAT_SIZE = 32
def get_images(paths):
images = []
for path in paths:
img = image.load_img(path, target_size=(224, 224))
x = image.img_to_array(img)
# x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
images.append(x)
return np.asarray(images)
def one_hot_encoding(labels):
labels = pd.Series(labels).str.get_dummies()
return labels
def split(files):
X_train, X_test = train_test_split(files, test_size=0.20, random_state=42)
X_train, X_valid = train_test_split(
X_train, test_size=0.10, random_state=42)
return X_train, X_test, X_valid
def get_labels(data_paths):
labels = []
for path in data_paths:
labels.append(os.path.basename(os.path.dirname(path)))
return labels
def fine_tune(model):
for layer in model.layers[:95]:
layer.trainable = False
for layer in model.layers[95:]:
layer.trainable = True
model.compile(
optimizer=SGD(lr=0.0001, momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
def get_data_paths():
data_folders = glob.glob(os.path.join('data', '*'))
train_paths = []
test_paths = []
valid_paths = []
for folder in data_folders:
files = glob.glob(os.path.join(folder, '*.jpg'))
train, test, valid = split(files)
train_paths = train_paths + train
test_paths = test_paths + test
valid_paths = valid_paths + valid
np.random.shuffle(train_paths)
np.random.shuffle(test_paths)
np.random.shuffle(valid_paths)
return np.asarray(train_paths), np.asarray(test_paths), np.asarray(
valid_paths)
def add_new_last_layer(base_model, nb_classes):
"""Add last layer to the convnet
Args:
base_model: keras model excluding top
nb_classes: # of classes
Returns:
new keras model with last layer
"""
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(128, activation='relu')(x) # new FC layer, random init
x = Dense(32, activation='relu')(x) # new FC layer, random init
predictions = Dense(
nb_classes, activation='softmax')(x) # new softmax layer
model = Model(inputs=base_model.input, outputs=predictions)
return model
def setup_to_transfer_learn(model, base_model):
"""Freeze all layers and compile the model"""
for layer in base_model.layers:
layer.trainable = False
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
def train(args):
import ipdb;
#ipdb.set_trace()
nb_classes = 6
nb_epoch = int(args.nb_epoch)
batch_size = int(args.batch_size)
train_paths, test_paths, valid_paths = get_data_paths()
print(f"No. of Train samples = {len(train_paths)} \n")
print(f"No. of Test samples = {len(test_paths)} \n")
print(f"No. of Valid samples = {len(valid_paths)} \n")
train_labels = get_labels(train_paths)
print(f'For Train = {Counter(train_labels)} \n')
train_labels = np.asarray(one_hot_encoding(train_labels))
test_labels = get_labels(test_paths)
print(f'For Test = {Counter(test_labels)} \n')
test_labels = np.asarray(one_hot_encoding(test_labels))
valid_labels = get_labels(valid_paths)
print(f'For Valid = {Counter(valid_labels)} \n')
valid_labels = np.asarray(one_hot_encoding(valid_labels))
train_images = get_images(train_paths)
test_images = get_images(test_paths)
valid_images = get_images(valid_paths)
# setup model
base_model = MobileNet(input_shape=(224, 224, 3),
weights='imagenet', include_top=False) # Not Icluding the FC layer
model = add_new_last_layer(base_model, nb_classes)
# for i, layer in enumerate(model.layers):
# print(i, layer.name)
# import ipdb; ipdb.set_trace()
for layer in base_model.layers:
layer.trainable = False
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# import ipdb; ipdb.set_trace()
weight_train_labels = [np.argmax(r) for r in train_labels]
weights = class_weight.compute_class_weight(
'balanced', np.unique(weight_train_labels), y=weight_train_labels)
class_weights = {0: weights[0], 1: weights[1]}
history = model.fit(
x=train_images,
y=train_labels,
batch_size=batch_size,
epochs=int(nb_epoch),
verbose=1,
shuffle=True,
validation_data=(valid_images, valid_labels))
model.save(args.model)
y_pred_class = model.predict(test_images, verbose=1)
y_pred_class = [np.argmax(r) for r in y_pred_class]
test_y = [np.argmax(r) for r in test_labels]
print('Confusion matrix is \n', confusion_matrix(test_y, y_pred_class))
print(confusion_matrix(test_y, y_pred_class).ravel())
if args.ft:
ft_epochs = args.epoch_ft
fine_tune(model)
history = model.fit(
x=train_images,
y=train_labels,
batch_size=batch_size,
epochs=int(ft_epochs),
verbose=1,
shuffle=True,
validation_data=(valid_images, valid_labels))
model.save(args.model_ft)
print('_______Results After Fine Tuning____________')
y_pred_class = model.predict(test_images, verbose=1)
y_pred_class = [np.argmax(r) for r in y_pred_class]
test_y = [np.argmax(r) for r in test_labels]
print('Confusion matrix is \n', confusion_matrix(test_y, y_pred_class))
print(confusion_matrix(test_y, y_pred_class).ravel())
if __name__ == "__main__":
a = argparse.ArgumentParser()
a.add_argument(
"--nb_epoch",
default=NB_EPOCHS,
help='Number of epochs for Transfer Learning. Default = 1.')
a.add_argument(
"--batch_size",
default=BAT_SIZE,
help='Batch size for training. Default = 32.')
a.add_argument("--model", help='Path to save model to.')
a.add_argument("--model_ft", help='Path to save fine tuned model')
a.add_argument(
"--ft", action="store_true", help='Whether to fine tune model or not')
a.add_argument(
'--epoch_ft',
default=NB_EPOCHS,
help='Number of epochs for Fine-Tuning for model. Default = 1.')
args = a.parse_args()
if args.ft:
print("Please make sure that you have added fine tuning epochs value")
train(args)
Raspberry Pi inference code
pi_trash_classifier.py
Long ago
Feb 15, 2019
You uploaded an item
Text
pi_trash_classifier.py
import keras
#from picamera import PiCamera
#from picamera.array import PiRGBArray
from keras.models import Model, load_model
from keras.applications import mobilenet
from keras.applications.mobilenet import preprocess_input
from keras.preprocessing import image
from keras.utils.generic_utils import CustomObjectScope
import numpy as np
import time
import cv2
import os
img = []
def pp_image():
global img
img = image.load_img('data/trash/trash1.jpg', target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return np.asarray(x)
prediction_list=['cardboard', 'glass', 'metal', 'paper', 'plastic', 'trash']
model=load_model('models/model1_org.h5', custom_objects={'relu6': mobilenet.relu6})
#camera = PiCamera()
#rawCapture = PiRGBArray(camera)
for i in range(10):
time.sleep(0.5)
try:
#camera.capture(rawCapture, format='rgb')
#img=rawCapture.array
#cv2.imwrite('pic.png', img)
pred_img = pp_image()
yo = model.predict(pred_img)
pred = prediction_list[np.argmax(yo)]
cv2.putText(img, pred, (10,1000), cv2.FONT_HERSHEY_SIMPLEX, 5, (0,0,0), 5, False)
name='img'+str(i)+'.png'
cv2.imwrite(os.path.join('prediction_images', name), img)
#rawCapture.truncate(0)
except:
print('Could not perform prediction')
camera.stop_preview()
Here is the cloud version from Clarify.io
trash_classifier.py
Long ago
Feb 15, 2019
You uploaded an item
Text
trash_classifier.py
import keras
from pypylon import pylon
from keras.models import Model, load_model
from keras.applications import mobilenet
from keras.applications.mobilenet import preprocess_input
from keras.preprocessing import image
from keras.utils.generic_utils import CustomObjectScope
import numpy as np
import matplotlib.pyplot as plt
import time
import cv2
import os
def pp_image(img):
img = image.load_img('pic.png', target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return np.asarray(x)
prediction_list=['cardboard', 'glass', 'metal', 'paper', 'plastic', 'trash']
model=load_model('models/model1_org.h5', custom_objects={'relu6': mobilenet.relu6})
camera = pylon.InstantCamera(pylon.TlFactory.GetInstance().CreateFirstDevice())
numberOfImagesToGrab = 100
camera.StartGrabbingMax(numberOfImagesToGrab)
converter = pylon.ImageFormatConverter()
converter.OutputPixelFormat = pylon.PixelType_BGR8packed
converter.OutputBitAlignment = pylon.OutputBitAlignment_MsbAligned
i=0
while camera.IsGrabbing():
time.sleep(0.005)
grabResult = camera.RetrieveResult(5000, pylon.TimeoutHandling_ThrowException)
if grabResult.GrabSucceeded():
# Access the image data.
print("SizeX: ", grabResult.Width)
print("SizeY: ", grabResult.Height)
#import ipdb; ipdb.set_trace()
img = converter.Convert(grabResult).GetArray()
cv2.imwrite('pic.png', img)
pred_img=pp_image(img)
yo=model.predict(pred_img)
pred=prediction_list[np.argmax(yo)]
cv2.putText(img, pred, (10,1000), cv2.FONT_HERSHEY_SIMPLEX, 5, (0,0,0), 5, False)
name='img'+str(i)+'.png'
cv2.imwrite(os.path.join('prediction_images', name), img)
i=i+1
#print("Gray value of first pixel: ", img[0, 0])
grabResult.Release()
if i==10:
break
Contents

Python, Java, ML
